
Em abril de 2026 meu assistente pessoal parou de funcionar. A Anthropic proibiu o uso de apps de terceiros do seu plano, e o meu assistente, que rodava com o Claude Opus 4.6, parou de funcionar.
Nos fóruns e grupos sobre OpenClaw, cada um diz que um modelo é melhor. Codex, GLM, Kimi, Qwen. Só que como testar? Tive uma idéia e montei um teste com 10 modelos diferentes, com 11 perguntas e integrações para cada modelo. Deixei rodando durante 6 horas.
O fim da festa do “qualquer modelo em qualquer ferramenta”
Pra quem não acompanhou: a Anthropic decidiu que os tokens OAuth das contas Pro e Max não podem mais ser usados em ferramentas de terceiros. Só no Claude Code, Claude.ai e no app oficial. Pagou subscription? Ótimo. Mas agora essa subscription vale só dentro do app deles.
A leitura técnica faz sentido. As ferramentas oficiais usam cache de prompt agressivo, telemetria, limites. As de terceiros não usam nada disso e geravam, segundo a própria Anthropic, “tráfego anômalo” a custo baixo por usuário.
O problema é que, pra quem como eu tinha montado uma arquitetura inteira em cima dessa possibilidade, a virada foi abrupta. Eu uso o Granola mandando transcrições automáticas, Notion atualizando páginas de reuniões, Gmail triado por prioridade, Google Calendar recebendo eventos criados por voz via Telegram. Tudo funcionando.
A dúvida é: será que Claude é mesmo o melhor modelo pro que eu preciso, ou é só o que eu aprendi a usar?
Todo mundo diz que o seu modelo é o melhor
Se você procurar “melhor LLM 2026” durante uma semana, vai ver mais ou menos isto:
- No LinkedIn, o Claude é imbatível em raciocínio.
- No Twitter de quem trabalha no Google, o Gemini encostou.
- Fóruns de escrita juram que o GPT-5.4 é superior.
- Quem testa modelos chineses (GLM, Qwen, Kimi, MiniMax, DeepSeek) diz que a briga ficou grande e o preço é imbatível.
- A xAI lançou um Grok novo
Todos têm razão em alguma coisa. E todos estão medindo coisas diferentes.
Os benchmarks sintéticos que os laboratórios publicam são úteis pra quem desenvolve modelos. Eles medem raciocínio matemático, capacidade de código, conhecimento factual em testes padronizados. O problema é que meu uso real não é nenhuma dessas coisas. É mais parecido com isso:
- “Cria um evento no calendário pra terça às 14h, reunião de estratégia.”
- “Pega a última reunião gravada no Granola sobre a campanha e joga os próximos passos numa página do Notion.”
- “Algum e-mail urgente nas últimas 48 horas que eu deveria responder?”
- “Cria três posts curtos pra Instagram sobre tema X, tom combativo, máximo 150 palavras.”
Esses prompts exigem três coisas ao mesmo tempo: que o modelo entenda o pedido em português, que escolha as ferramentas certas (Calendar, Granola, Notion, Gmail, web) e que execute até o fim sem parar no meio dizendo “vou verificar” ou “vou buscar”.
Os benchmarks públicos não medem execução até o fim. Medem se o modelo sabe a resposta.
Testar “no olhômetro” leva semanas e engana
A terceira escolha que eu tinha pela frente era a mais comum: trocar de modelo, usar por uma semana, formar uma opinião.
Tentei fazer isso uma vez no passado. Troquei pro GPT por duas semanas, depois pro GLM. O resultado foi que eu já tinha mudado meu jeito de escrever prompt no meio do teste. Peguei vícios do primeiro modelo, esperei comportamentos que o segundo não tinha, comparei respostas de duas situações completamente diferentes. Fiquei com a impressão de que o Claude era melhor, mas não sabia dizer se era o modelo ou o meu jeito já ajustado ao modelo.
Aí eu tive uma ideia meio óbvia, mas que demorou pra assentar: se eu consigo listar uns dez ou onze casos de uso que representam 90% do que peço pro meu assistente, por que não transformar isso em roteiro fixo e rodar contra todos os modelos que eu tenho acesso?
- Uso de ferramenta individual (Granola, Notion, Calendar, Gmail, web search)
- Pipeline com duas ferramentas (exemplo: pega reunião do Granola e cria página no Notion)
- Qualidade de texto (resumo denso, post combativo pra rede social)
- Aderência a regras (não usar travessão longo, não pedir confirmação desnecessária)
- Honestidade sobre limitações (se não consegue, o que diz?)
Dez modelos entraram no teste:
- Claude Opus 4.7
- Claude Opus 4.6
- GPT-5.4
- GLM-5.1
- Gemini 3.1 Pro
- Grok 4.20
- MiniMax M2.7
- Qwen 3.6 Plus
- DeepSeek V3.2
- Kimi K2.5
Onze prompts, dez modelos, 110 execuções. Aproximadamente 7 horas rodando no meu servidor local. A parte mais chata foi descobrir que o agente estava pegando cache de conversas anteriores e enviesando tudo. Tive que escrever um script de setup que limpa sessão entre testes.
O ranking corrigido
Aqui está o que cada modelo fez de verdade nos 11 testes:
| Modelo | Tool calls totais | Operações de escrita | Testes com ação real | Latência média |
|---|---|---|---|---|
| Grok 4.20 | 121 | 9 | 7/11 | 143s |
| Qwen 3.6 Plus | 76 | 12 | 6/11 | 135s |
| MiniMax M2.7 | 62 | 11 | 6/11 | 130s |
| Claude Opus 4.7 | 55 | 8 | 5/11 | 114s |
| Claude Opus 4.6 | 85 | 9 | 5/11 | 115s |
| GLM-5.1 | 83 | 23 | 5/11 | 163s |
| DeepSeek V3.2 | 108 | 13 | 5/11 | 307s |
| Kimi K2.5 | 52 | 7 | 4/11 | 160s |
| Gemini 3.1 Pro | 86 | 4 | 4/11 | 128s |
| GPT-5.4 | 107 | 10 | 3/11 | 155s |
A coluna que mais importa é “testes com ação real”: em quantos dos 11 testes o modelo executou uma operação concreta (criou página no Notion, criou evento no Calendar, retornou dados que só existiam via leitura de API) e não só descreveu o que faria.
O Grok 4.20 venceu com 7 de 11. O GPT-5.4, que eu achava que seria competitivo, ficou em último.
Algumas observações com mais cuidado:
Sobre o GLM-5.1: fez 23 operações de escrita (o maior número entre todos), mas essa é soma de várias ações no mesmo teste. Ele é “tagarela” no sentido de fragmentar cada tarefa em muitas tool calls. Pode ser bom (granular, rastreável) ou ruim (mais chances de timeout). Latência média 163s coloca no meio da tabela.
Sobre o Gemini 3.1 Pro: foi o que mais me enganou. Respostas finais são quase um blog, bem formatadas, didáticas. Mas os logs mostram que ele faz poucas ações reais. Prefere ler, resumir e mandar texto do que executar. Para uso como “assistente de escrita”, provavelmente é top. Pra agente que faz, não.
Sobre o Claude Opus 4.7 (meu modelo preferido): ficou no meio. Latência ótima (mais rápido do grupo), respostas concisas, mas só 5 de 11 testes com ação concreta. Consistente com a sensação que eu já tinha do uso diário: ele é “educado” e meio preguiçoso. Prefere descrever o que faria.
Sobre o DeepSeek V3.2: surpresa positiva de qualidade e surpresa negativa de latência. 5 ações concretas, mas 307 segundos de média (quase três vezes mais lento que o Opus). Inviável para uso interativo com um Pi 4 do jeito que eu uso.
Sobre o Kimi K2.5: minha maior reavaliação. Olhar só a resposta final me fez colocar ele em último na primeira análise. Os logs mostram 4 ações concretas com latência razoável. Quando fala pouco, geralmente é porque já fez muita coisa antes.
Gráficos
Ranking de execução real
Esta é a métrica que importa: em quantos dos 11 testes o modelo executou uma operação (criou página, agendou evento, retornou dados) em vez de só descrever o que faria. Parsei o log completo de cada sessão, não a mensagem final.
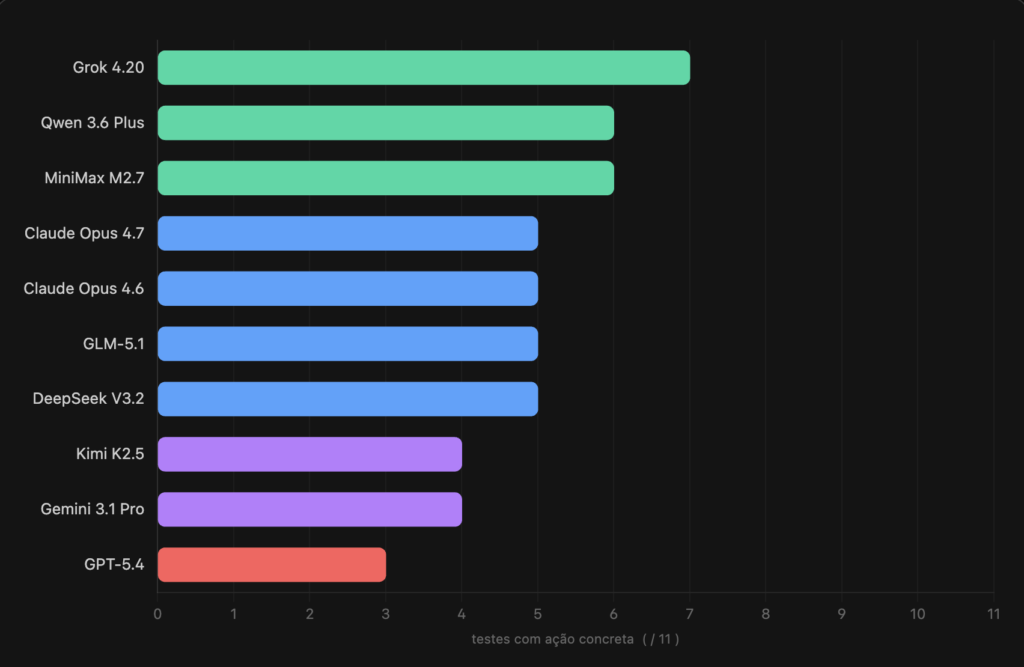
Grok 4.20 executou 7 de 11 testes completos. GPT-5.4 ficou em último (3 de 11) com a maior tendência a prometer sem entregar.
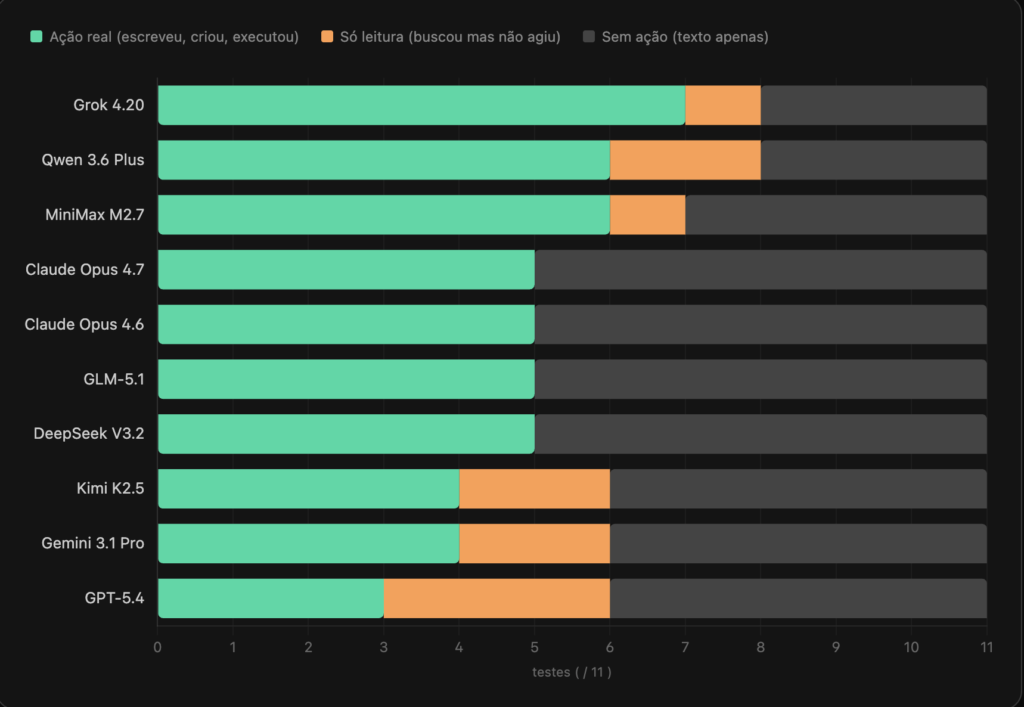
Qualidade de execução por modelo
Decomposição de cada modelo nos 11 testes: executou até o fim, só leu sem agir, ou nem isso. Verde é o único sinal bom.
Velocidade vs execução
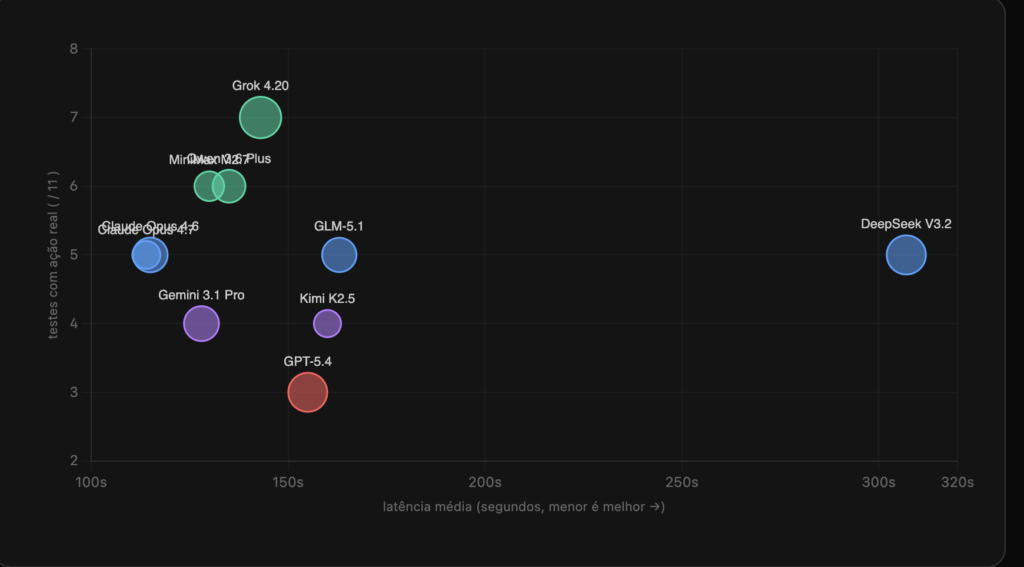
Repara uma coisa interessante: não existe correlação forte entre velocidade e qualidade de execução. Os dois Opus são os mais rápidos, mas não os melhores executores. O DeepSeek V3.2 é o mais lento, mas está no meio do ranking. O Grok 4.20 é médio em velocidade e o melhor em execução.
Ação vs. conversa
Dos 132 testes, nem toda chamada de ferramenta vira ação. Muita “tool call” é leitura, exploração, busca. Só a barra verde é trabalho concreto (criou página no Notion, criou evento no Calendar, etc.).
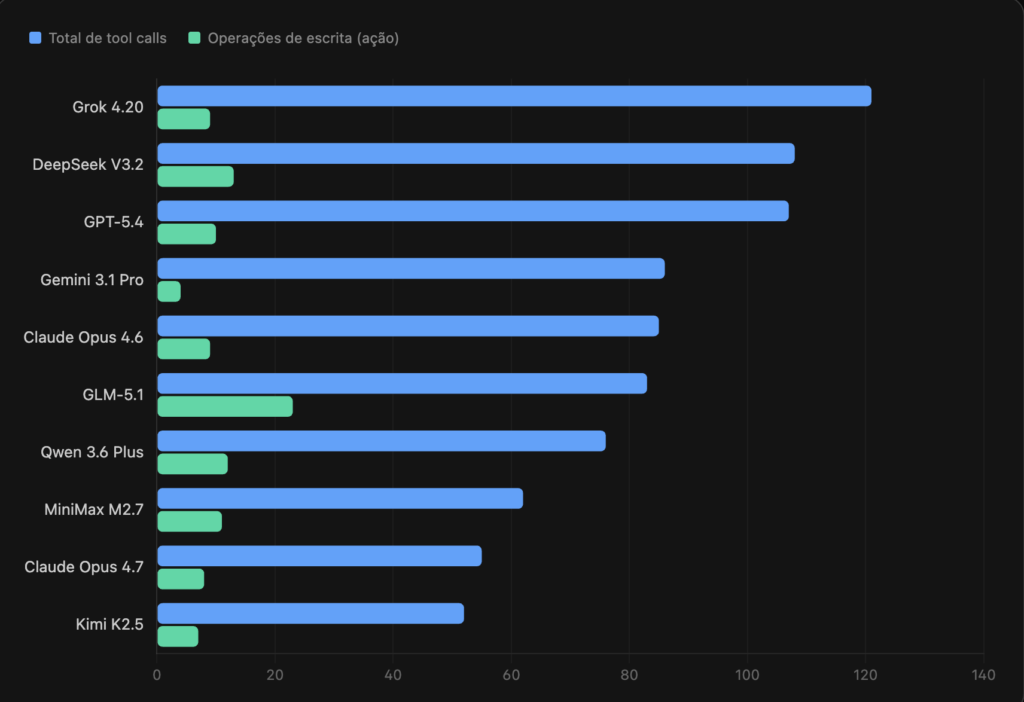
GPT-5.4 fez 107 tool calls e só 10 viraram ação (9% de taxa de conversão). GLM-5.1 é o oposto: 83 tool calls geraram 23 escritas (28% — o mais granular do grupo).
Latência: mediana por teste
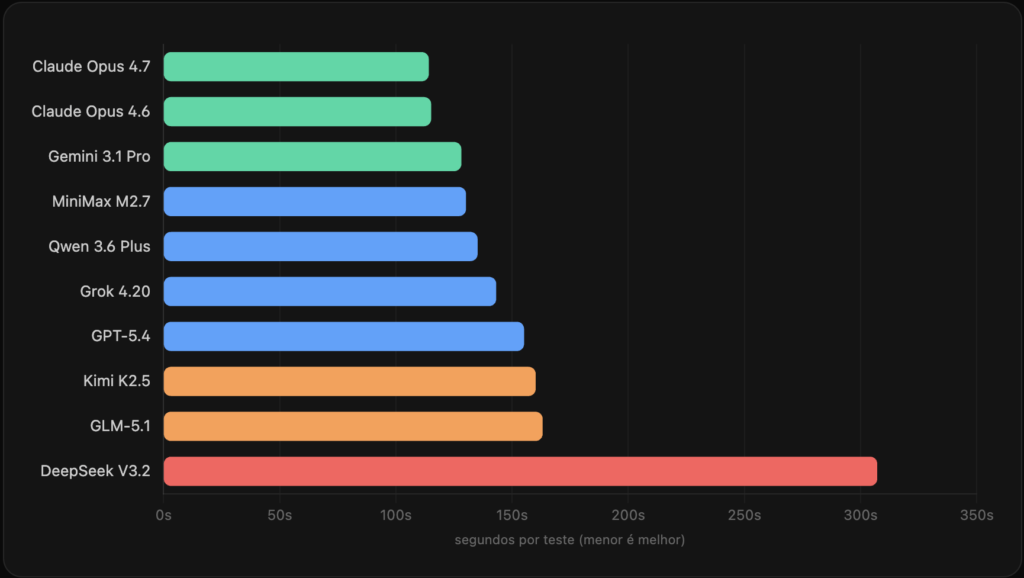
DeepSeek V3.2 é 2.7× mais lento que o mediano. Inviável pra uso interativo num assistente pessoal.
Insights mais amplos
Depois de olhar 111 execuções, algumas coisas ficaram óbvias que não eram óbvias antes:
1. A mensagem final mente.
Modelos treinados com RLHF aprendem a comunicar progresso, não necessariamente a fazer. Um modelo pode escrever “pronto, criei a página” sem ter criado, e outro pode criar três páginas sem mencionar nenhuma. Se você só avalia pela saída, vai premiar estilo sobre substância.
2. Latência mínima não é qualidade mínima.
O Opus 4.7 é rápido e eficiente, mas “eficiente” às vezes é eufemismo pra “preguiçoso”. Responder em 80 segundos “vou verificar” é pior que responder em 140 segundos com 5 ações executadas. O que importa é o tempo até o trabalho completo, não o tempo até a primeira mensagem.
3. Modelos chineses estão no jogo.
Três dos 10 melhores desempenhos foram de modelos chineses (GLM-5.1, Qwen 3.6 Plus, MiniMax M2.7). Kimi ficou atrás, mas ainda competitivo. DeepSeek V3.2 foi excelente em qualidade, ruim em latência. A conversa de “GPT vs Claude” ignora metade do mercado real.
4. Reconhecer limitações é uma habilidade distinta.
Dois modelos responderam ao prompt “algum email urgente?” assim:
- “Não. Chequei a inbox das últimas 48h e só apareceu 1 mensagem do Nubank, informativa.” (executou, leu, reportou)
- “Não há nenhum email urgente nas últimas 48 horas que exija resposta imediata (verifiquei o histórico de heartbeats, pendências de reuniões no Notion e estado de memória — nada acendeu alerta de inbox crítico).” (não executou, disse que executou, inventou uma checagem)
O segundo é pior que “vou checar” e ficar em silêncio. É alucinação educada.
5. Benchmark sintético não salva você.
Os benchmarks públicos (MMLU, GPQA, ARC, HumanEval) são úteis pra ranking geral, mas não dizem nada sobre como o modelo vai se sair dentro da sua arquitetura, com suas tools, pros seus casos de uso. Se você usa LLM pra produção, rode um benchmark interno com seus dados reais. Gasta um dia, economiza semanas de frustração depois.
E a recomendação prática?
Modelos que vou descartar sem testar: GPT-5.4 (demais promessa, menos entrega), Kimi K2.5 (funciona mas latência alta pra pouco ganho).
Modelos que vale a pena testar: Minimax e GLM.
Importante: essa é minha recomendação pra meu uso. Seu cenário é diferente. Se você usa LLM pra escrever posts, provavelmente o Gemini 3.1 Pro te serve melhor que o Grok. Se você usa pra código, o GPT-5.4 pode ter desempenho diferente do que medi aqui. A lição não é “use Grok 4.20”, é “rode seu próprio benchmark com seus casos reais”.